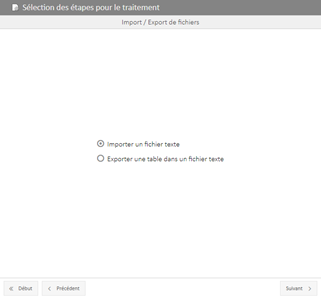
Ce traitement permet d’implémenter votre base de données à partir du
contenu d’un fichier de type TXT ou CSV.
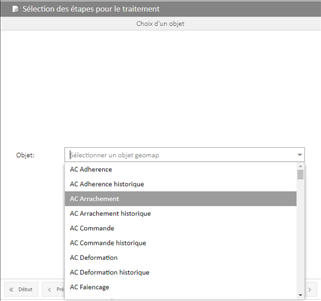
► Choix de la rubrique : Sélection de la rubrique à traiter dans la liste des rubriques de type linéaire ou ponctuel :
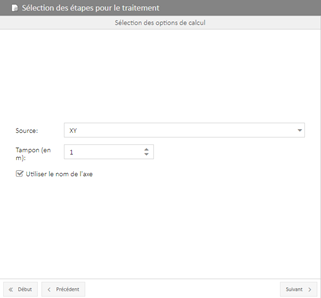
► Sélection de la manière où les données seront géocodées. Trois sources possibles :
- PrAbs : dans le fichier à importer, nous avons des informations en Axe, PR + Abscisse ;
- Cumul : dans le fichier à importer, nous avons des informations en Axe, Abscisse cumulée ;
- XY : dans le fichier à importer, nous avons des informations en X,Y pour une rubrique ponctuelle et (X,Y) de début et (X,Y) de fin pour une rubrique linéaire :
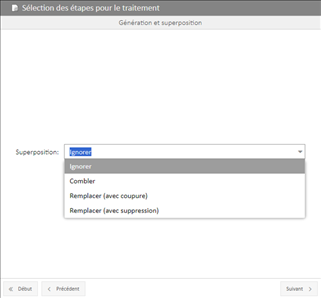
► Choix du fichier à intégrer et choix du Séparateur : Sélection du type de séparateur utilisé dans le fichier texte source.
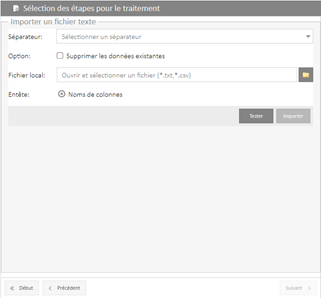
- Actions :
· Ajouter : ajoute les enregistrements à la base de données,
· Remplacer : vide la base de données avant d’importer les données.
- Fichier local : chemin d’accès au fichier source.
La correspondance entre le fichier source et la base de données se fait
à partir du nommage des en-têtes du fichier source.
Pour les champs
« systèmes », on impose les nommages suivants :
► TERRITOIRE
► VOIE
► AXE
► CUMULD
► CUMULF
► PLOD
► ABSD
► PLOF
► ABSF
► XD
► YD
► XF
► YF
► ACCROCHAGE
Pour les champs « non-systèmes » qui sont les attributs permettant de
caractériser votre rubrique, le nommage
devra correspondre exactement à celui du nom de la variable dans l’Objet.
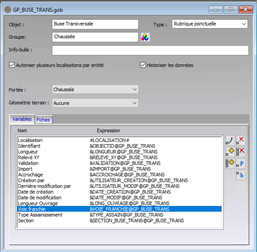
Dans l’exemple ci-dessous, pour l’ajout des
trois dernières variables, on devra noter dans l’entête du fichier à
importer :
► Voie franchie
► Type Assainissement
► Section
De plus, il est impératif de respecter les contraintes propres à la
base de données. Par exemple, si un champ a une contrainte non nulle, il faudra
obligatoirement qu’il soit renseigné pour chaque enregistrement.
Le champ identifiant sera automatiquement renseigné en fonction des
paramétrages du studio (génération Max + 1 ou utilisation d’une séquence).
Il n’est pas obligatoire de paramétrer l’intégralité des champs de la
table destination dans le fichier source. Par exemple, vous pouvez très bien
intégrer uniquement les champs « NOM_VOIE », « AXE »,
« CUMULD » et « CUMULF », à condition qu’aucun autre champ
de la table n’ait une contrainte l’empêchant d’être nul.
Les géométries seront calculées automatiquement.
► Celle de la localisation sera la géométrie à l’axe (superposée à l’axe) ;
► Celle de la table principale sera identique à celle de la localisation si on est en portée « Chaussée », « sens de circulation » ou « Bdr ». Dans le cas d’une portée « Extérieure », la géométrie sera décalée de la valeur du décalage indiqué dans le fichier csv.
Exemple de fichier CSV source :

!
Attention de bien vérifier l’orthographe
et la casse des en-têtes de colonnes et de s’assurer qu’elles correspondent
parfaitement avec les noms de champs de la table destination.
Il est possible avec le bouton « Tester » de valider la pertinence des données de localisations présentes dans le fichier. Le système sort un rapport d’erreur.
Rien n’a été ajouté dans la base de données pour l’instant.
Il vous est donc possible de modifier le fichier texte de manière à le retester et à l’importer.
Ensuite, vous pouvez lancer le traitement avec le bouton « Importer ».
Le résultat du traitement est :
► Traitement réussi avec succès ;
► Message d’erreur. Voir dans le log le détail de l’erreur, il s’agira généralement d’une erreur au niveau du format du fichier source.