

A Rules Based Approach to Data Validation and Continuous Data Improvement
A Rules Based Approach to Data Validation and Continuous Data Improvement
Author: Bob Chell, CPO

On the edge of the fourth industrial revolution, digital technology is playing an ever-increasing role in public sector operations. The cornerstone of this digital age is data, and more importantly the quality of that data. We frequently hear that society wants to be an increasingly data-driven society, with data forming the foundation of evidence for decision making. Not only does this create confidence in decisions being made, but transparency and evidenced reasoning. To use a popular phrase “everything happens somewhere”, and therefore location is a key component to the data behind our data driven society.
Good quality data
This new desire to be a truly data driven society is great, but we need to think practically about how we can become truly data-led with good quality data. In the past this would have meant embarking on a long and expensive digital transformation programme, but with the introduction of the OS Data Hub, public sector organisations can use data made available via the Public Sector Geospatial Agreement along with our technology to quickly validate and correct their geospatial data.
Watch: How to Build Trust in Geospatial Data
A short overview of 1Spatial
Our core business is in making geospatially-referenced data current, accessible, easily shared and trusted. We have over 30 years of experience as a global expert; uniquely focused on the modelling, processing, transformation, management, interoperability, and maintenance of spatial data – all with an emphasis on data integrity, accuracy and on-going quality assurance. We have provided spatial data management and production solutions to a wide range of international mapping and cadastral agencies, government, utilities and defence organisations across the world. This gives us unique experience in working with a plethora of data (features, formats, structure, complexity, lifecycle, etc.) within an extensive range of enterprise-level system architectures.
The rules engine 1Integrate
One of the key components of the 1Spatial Platform is our rules engine. We use this in a range of our products, for example in 1Integrate, that enables users to collaboratively define and enforce business rules to measure and maintain spatial data quality, all created, tested and released from within a no-code environment. This environment gives us a highly configurable logic-based data validation and manipulation engine based on user-defined rules as well as an Enterprise Metadata Repository that provides a central, unified location for storing ontologies, rules and process definitions as well as an archive of processing results.
With 1Integrate you can:
- Define data stores to access data from external data sources
- Configure schema mapping to specify how the data should be organised
- Run rule discovery to identify potential rules from patterns in your data
- Use the rule builder to define rules that apply to your data
- Define actions to correct data that does not conform to your rules
- Set up action maps to specify when actions should be applied
- Define sessions to implement data processing workflows
Rules can be used in a wide range of scenarios, as you look to establish control, consistency and confidence in your data.
Examples of data rules:
- Powerful spatial and non-spatial rules to easily manage, validate and process data by considering not just individual features but the relationships between them
- Re-use content of existing rules and actions to speed up the authoring of new rules
- Apply topology rules for structuring and snapping your data
- Define rules to create a network graph of your data so you can analyse global connectivity across objects in your data
- Positional Data Shifting - Shift data to deliver positional accuracy improvements using powerful rule algorithms
- Define data models with class hierarchy (ontologies) to easily apply rules and re-use existing rules
The 1Integrate no-code environment means you can also perform system management tasks, such as:
- Roles - Managing user privileges and roles
- Backup and Restore of data stores, rules and actions
- Purging Enterprise Metadata Repositories when managing the automated continuous delivery of your systems and solutions
Our rules-based approach is based on a very simple concept, that we describe as Fact – Pattern – Action. Given some facts, if they meet any of the patterns/rules, perform the defined action. We’ve exposed this rules-engine by making sure our rules are declarative – rule separated from processing, and extendable into pluggable actions, which allows us to extend basic levels of reporting, reconcile data issues or create new data.
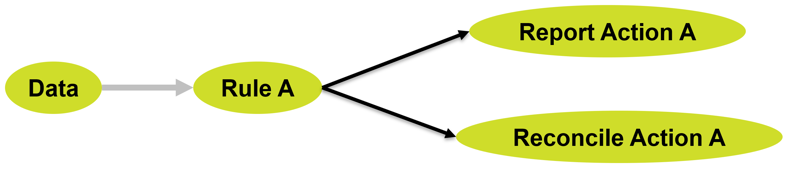
A rule needs to answer questions in the form "Given an object from the class, what does this rule require of the object in order for it to be valid?"
This means rules are really simple – they tell us if something is true (valid) or false (not valid), and it is easy to trace what the rule did, as it is always represented by a logical condition.
A simple rule might check the attributes of a feature, or to perform a simple geometry check. More complex rules check the feature against other features from the same or different sources, checking for conditions like the existence of other features, checking that all objects meet a particular condition are true, or aggregating values to perform your tests. Examples might be:
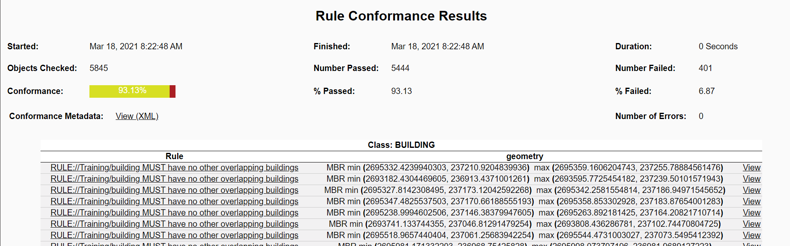
- This building MUST have no other overlapping buildings
- Pipes connected to a valve MUST be of the same pressure
- The maximum voltage of all connected cables MUST BE EQUAL TO X

Rules greatly reduce the time taken to check for errors and provide a rigorous, efficient, and cost-effective mechanism to measure and maintain spatial data quality. When an operator is viewing the data, errors in the graphical representation can be easily missed. The rules give us facts about the data, so that errors can be are corrected, automatically and/or manually, and so you can continuously monitor and assess rule conformance against quality targets.
The same Fact – Pattern – Action concept also works for data enhancement and transformation. We call these actions. Unlike a rule, an action does not return true or false but still performs logically constructed checks on the features, either a single task or a series of tasks, linked together in a sequence or loop. Tasks typically achieve their aims in three ways:
- Change the data (create an object, delete an object, update an object and assign a value to an attribute).
- Report (produce information to appear in the task's XML report).
- Run a built-in operation (a packaged piece of logic in a single function).
Rules use cases
There are many use-cases for enhancing and transforming data using intelligent contextual actions, such as:
- Comparing two sources of the same information to get the best of both, for example if one data source has accurate geometries and the other has accurate attribution.
- Collating data from different countries or regions to ensure that they are consistent, aligned at the edges and contain no duplication.
- Transforming cartographically-oriented or linear data to produce seamless, polygonised, classified, real-world object-based spatial data.
- Matching possibly incomplete records (such as addresses) from one data source to the best matching record from a master data source.
- Generating a less detailed and intelligently simplified "generalised" or "schematised" version of the data from a ‘single source of truth’ master dataset while maintaining data connectivity and correctness.
- Transforming data from one structure to another using business rules to map the objects and attributes. Typically this requires intelligent reclassification and inferring of new information based on the surrounding data.
Topology management
Another important feature I’d like to share, which is also linked to rules, is the Topology Management capability. Many of the components available on the 1Spatial Platform include the topology management engine. Topology management means taking spatial data and automatically creating topological nodes, edges and (optionally) faces that represent each unique or shared part of the geometries. This process snaps the geometries together and means that any edits to the features will automatically update the topology to keep it synchronised, and any update to the topology will update the features automatically.
Topology management provides a number of benefits including:
- Snapping data together to clean it. The process of building topology for a set of data will snap the features together using rules within user-controlled tolerances. This means that small gaps, overlaps, undershoots and overshoots are automatically removed from the source data
- Maintaining connectivity when modifying data. Building topology allows interactive editors or automated processes to update the shared parts of features to keep them connected for example when reshaping or simplifying the shared boundary of adjacent polygons, or when moving the connection points between lines in a network. By making the update to the topology edges and nodes, the connected features are all moved in synchrony using rules
- Use the geometries of holes, splits or overlaps to create new data. For polygon-based data, any holes in the coverage of data are represented by topological faces. Actions can be used to find geometries of these faces to generate new features that fill these holes. For a network of lines, the sections of line between intersections exist as topological edges and using the geometry of these edges makes it easy to create a version of the network that is split at intersections.
The Little Book of Spatial Data Management
If you would like to find out more about how we use rules to validate and manipulate spatial data. Download our little book.
Download