Managing and harnessing unstructured information across the built environment lifecycle
Supply chains across the plan, design, build and operate stages of the built environment lifecycle generate huge amounts of information. This information can be structured, such as BIM model files, GIS databases and drawing files, and unstructured such as photographs, video, emails, and documents, supplied as PDF and text files. Unstructured information can account for over 60% of all project information. Managing structured information automatically using Extract, Transform and Load (ETL) approaches is well understood but the same cannot always be said for unstructured information.
The Infrastructure and Projects Authority (IPA) “Transforming Infrastructure Performance: Roadmap to 2030” information management mandate recommends that asset owners should have a digital mechanism for defining their information requirements and then procuring, receiving, assuring, and immutably storing, via a system of record, the information that they procure. This means that supply chains and asset owners have a need to manage and harness both structured and unstructured information.
1Spatial have been exploring ideas around an automated process for extraction, assurance, and reporting of unstructured information; with a specific focus on drawing information in PDF format. The process focuses on some fundamental ideas of information assurance that are key to information acceptance but often fall under a manual task that can be time consuming and costly. A major challenge faced by data and information management professionals working in sectors like transport, utilities, and public sector across the built environment lifecycle is trying to manage and harness unstructured information. Most organisations have accumulated and continue to accumulate massive amounts of unstructured information. The volume, variety, and velocity of unstructured information means that organisations often find it difficult to uncover the insights they need from unstructured information. Many organisations are sitting on silos of legacy unstructured information that are not always managed and/or put to good use.
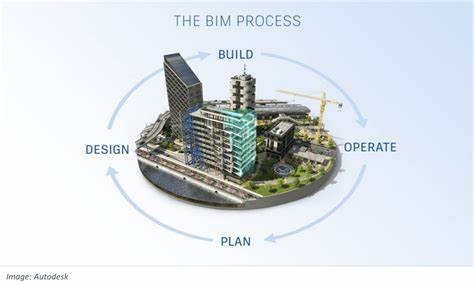
Managing unstructured information is crucial for organisations to unlock valuable insights, improve decision-making, and enhance efficiency. There is a need to turn unstructured information into structured information to serve plan, design, build and operate business purposes.
Image: Autodesk
Harnessing unstructured information across supply chains
Unstructured information is created, used, and exchanged across supply chains and asset owners. Contractors, consultants, and their project delivery teams create, use and exchange “as designed models” and “as built models”, which includes unstructured information.
Contractors exchange unstructured information with asset owners for project “handover”. Asset owners need to harness unstructured information, as part of their “Asset Information Models” to operate and maintain diverse types of built environment assets - such as buildings, road networks, railway lines, airports, flood defences or power stations. Asset owners need structured information to measure, model, monitor and manage assets.
Managing and harnessing all types of information is the foundation (system of record) for asset owner digital transformation, for example, implementing digital twins. Information management approaches are needed for harnessing both structured and unstructured information.
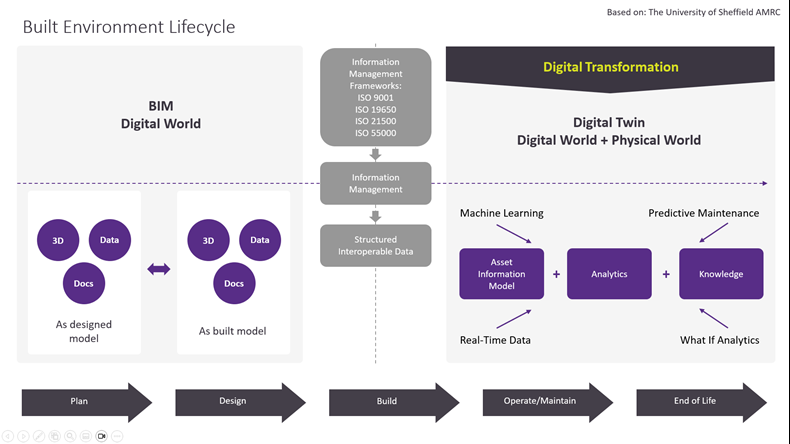
Managing unstructured information
Whilst structured information is information that is stored in clearly defined data types that can easily be imported into a relational database, and queried with Structured Query Language (SQL), unstructured information cannot be stored as efficiently in structured data repositories. Often unstructured information is stored as files in a Common Data Environment (CDE).
Individual departments or teams within organisations typically collect their own information and store it in different formats and in different systems. Unstructured information often needs to be checked for quality before it can be organised. It can be challenging for organisations to check and prepare massive amounts of unstructured information. As organisations’ unstructured information increases, there is a need to store it somewhere, which adds to the costs of managing information.
Information management approaches for understanding, extracting, checking, reporting, and accepting unstructured information are key to increasing overall information quality, integration, and use of structured information across the built environment lifecycle.
Accuracy, completeness, uniqueness, validity, timeliness, and consistency are all qualities of unstructured information:
- Accuracy – unstructured information is correct in all details and is a true record of the entity it represents.
- Completeness – unstructured information has all of the necessary attribute values relative to its intended purpose.
- Uniqueness – a single representation exists for each entity or activity.
- Validity – unstructured information conforms to all standards expected.
- Timeliness – unstructured information is easily accessed or available when required.
- Consistency – an entity that is represented in more than one unstructured information store that can be easily matched.
What can be done to manage and harness unstructured information?
Understanding unstructured information
To effectively manage unstructured information, organisations need to first understand their unstructured information and establish such things as; how much unstructured information they have, who owns the information, where is the information stored, what is the quality of the information and who can or should access the information. Understanding is the first step towards harnessing unstructured information.
Organise
Inevitably, with diverse and siloed unstructured information repositories, there is a need to sort and organise individual files before they can be managed and harnessed. At this stage, there is the consideration as to whether an information discovery exercise is needed that can form the basis for data cataloguing and metadata. All technical documents produced as part of a project contain metadata. Anything found within a title block or a document’s header, or footer has metadata, for example, a drawing will have a title and a date of issue.
Extracting unstructured information
To harness unstructured information organisations often need to take this unstructured information, extract content in some way, transform it into some form of structure, then visualise and analyse.
Checking unstructured information
There is then the need to assure the qualities of this content, often against other records. For example, metadata, business asset references or specific information requirements. The ISO 7200 standard specifies the mandatory and optional data fields for title blocks and document headers. In doing so, it provides a consistent name for each field, as well as its recommended character length. ISO 7200 provides a useful set of fields for checking unstructured information.
Reporting unstructured information
Once assured, there is the need to report conformance against other records. Reports can be shared with internal teams and/or the external supply chain.
Accepting unstructured information
Organisations should only accept unstructured information once it has been checked and conforms to other records.
Storing extracted unstructured information
Quality unstructured information that is extracted as structured information can be stored in a data repository, for onward business use. As described previously, structured information is the foundation for digital transformation.
What have 1Spatial been doing?
1Spatial have been exploring ideas around an automated process for extraction, assurance, and reporting of unstructured information; with a specific focus on drawing information in PDF format.
The process focuses on some fundamental ideas of assurance that are key to information acceptance but often fall under a manual task that can be time consuming and costly. This includes a file’s layout, it’s metadata and keywords content. Information is extracted, interpreted, and questioned. A rules-based approach can be used to question information within the PDF formatted files and determine whether information is conformant to reference sources.
Insights can be gained from unstructured information content using a hybrid of different techniques including feature extraction, machine learning and artificial intelligence. Rules-based techniques can assure, compare to reference sources, and ultimately organise and report insights. Rules are typically configured from defined standards and specifications and stored as a rules catalogue. This provides a clear indication as to what is required and what checks are applied. This is essential to effective collaborative exchange of information throughout the supply chain and the built environment lifecycle.
The process that 1Spatial has explored for managing and harnessing unstructured information uses Safe Software’s Feature Manipulation Engine (FME) platform and integrates with the Asite CDE. The process automatically extracts, checks, and reports insights, for example, title blocks from PDF files. The link with Asite proves how the process can be seamlessly integrated into existing information management tools and workflows.
1Spatial have approaches for managing and harnessing structured and unstructured information, utilising toolsets including FME and 1Integrate. Managing structured and unstructured information is crucial for organisations to unlock valuable insights, improve decision-making, and enhance efficiency. There is a need to turn unstructured information into structured information to serve many business purposes.
For more information, take a look at 1Spatial’s Built Environment web page.
Authors: Matthew White and Adrian Porter, 1Spatial
What next?
If you would like to find out more about managing and harnessing structured and unstructured information, speak to one of our experts.
Contact Us