Geospatial: The Hidden Power Behind Renewable Energy Success - Part Three
Automating data governance and quality checks: from principle to practice
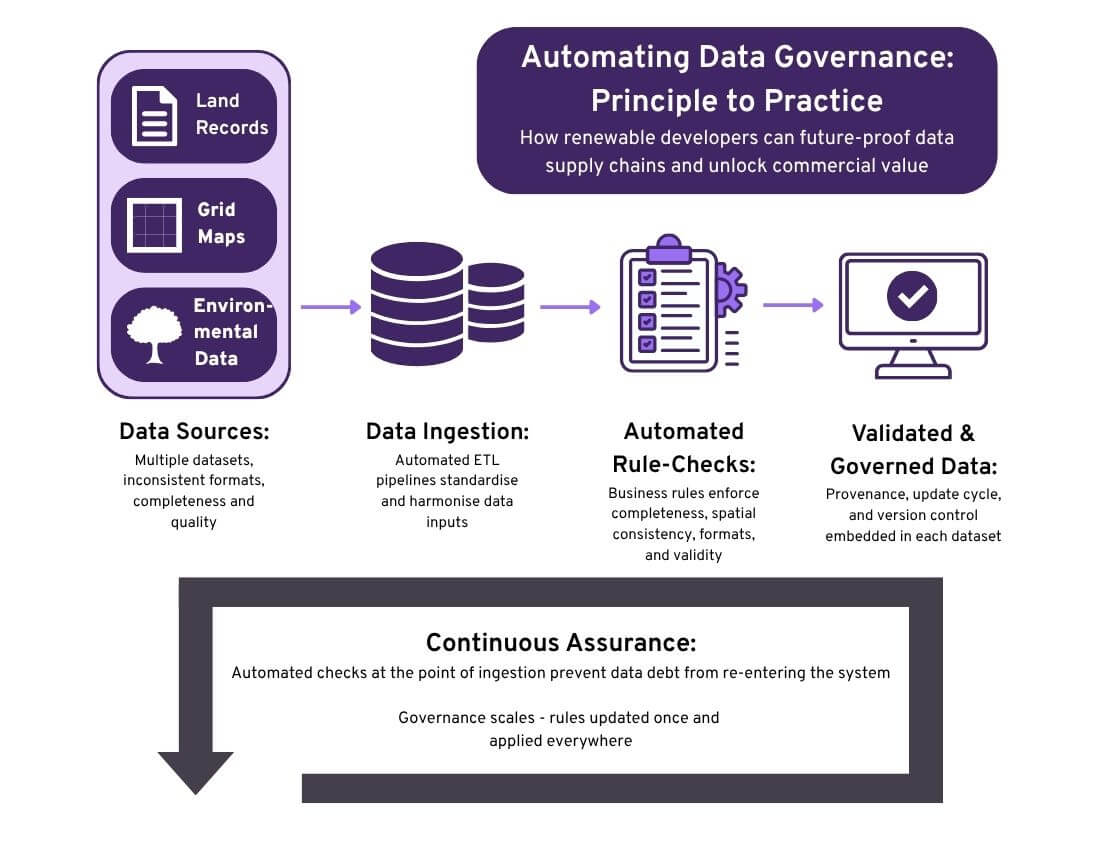
Renewable developers depend on data. Land ownership records, grid capacity maps, environmental designations all flow into decisions about where and how projects are built. But much of this data is messy: formats differ, attributes are missing and updates lag behind reality. Manually cleaning and checking datasets can work at small scale, but it simply doesn’t scale if you have ambitions to increase the size and complexity of your pipeline.
Rules-based automation changes the picture. By codifying what ‘good data’ looks like, developers can embed quality and governance checks directly into their data supply chains. The result is less time spent problem-solving, and more confidence in every dataset that underpins strategic and operational decisions.
What rules-based checks look like
At its core, rules-based automation means defining business rules once and applying them consistently, every time new data enters the workflow. Some hypothetical examples to illustrate:
- Attribute completeness e.g., every land parcel must have an ownership ID and tenure status. If records are missing, they are flagged instantly.
- Spatial consistency e.g., site boundaries must not overlap or be within a certain tolerance of protected areas. Any encroachment is identified before it becomes a costly planning issue.
- Format and units e.g., grid connection capacities must be expressed in MW, not kW. If inconsistent units appear, the technology normalises them or reports them.
- Currency of data e.g., environmental datasets older than three years must be marked as out-of-date. Teams are alerted automatically when updates are required.
These are simple examples, but the principle extends to hundreds of checks across multiple datasets. Crucially, automation means these checks run every time data changes, not just when someone remembers to do a spot-check.


Governance in practice
Automated checks do more than enforce quality, they strengthen governance by embedding discipline into data supply chains. Each dataset carries its provenance, update cycle, and version history. This makes it possible to answer questions like:
- Where did this data come from?
- When was it last updated?
- Which version fed into last year’s permit application?
A further challenge is the data generated by third parties, for example through environmental or engineering surveys. These specialist datasets are essential but often arrive in formats that differ from internal standards. Without cleansing and standardisation, integration into the geospatial data landscape can introduce errors or inconsistencies. By applying rules-based automation at the point of ingestion, developers ensure survey outputs are validated and aligned before they enter core systems.
Just as importantly, automation makes governance future-proof. When developers re-engineer data supply chains to include automated checks at the point of extract and load, they avoid reintroducing ‘data debt’ every time new datasets are brought in. The company’s asset database stays clean, because new errors are intercepted before they can accumulate. This shift, from one-off cleansing projects to continuous assurance, means quality is sustained across the portfolio, not just temporarily improved.
Why this matters for the business
Investing in automated data governance and quality checks pays off in ways that matter commercially:
- Fewer late-stage surprises: constraints and errors are caught at feasibility, not permitting.
- Efficiency at scale: onboarding new projects or markets doesn’t mean reinventing quality processes.
- Portfolio resilience: data is trusted and consistent across multiple regions, enabling better strategic planning.
- Investor confidence: audit trails and transparent rules strengthen due diligence and financial models.
- Regulatory adaptability: when policies shift, for example new biodiversity reporting requirements, rules can be updated once and applied everywhere.
Looking ahead
Even with strong governance, gaps in asset data remain a challenge. Emerging approaches such as AI-enabled inference are beginning to help fill these gaps intelligently, for example by predicting missing attributes or flagging anomalies in grid or asset records. While still evolving, these techniques point to a future where data quality is not just preserved, but actively enhanced. This will be the focus of the next article in the series.
Closing thought
Rules-based automation turns data governance from a reactive task into a proactive advantage. For renewable developers, it’s a way to move faster, reduce risk, and build credibility at scale.
How close are your current processes to delivering this kind of repeatable, auditable quality assurance?
Article written by Andrew Groom, Head of Energy
Get in touch if you’d like help reviewing your current geospatial workflows.
How confident are you that your geospatial data strategy will keep pace with your growth plans? If this is an area you’re working on? I’d be interested to hear what’s proving effective, or where the challenges lie.
Contact