


Data Validation
Automatically validate your data
Data validation can be a headache.
- How do you keep your data current without regular updates?
- How do you validate your updated data?
- And, how do you continually keep core data both reliable and accessible?
The 1Spatial automated, rules-based approach using our powerful rules engine 1Integrate, validates data at the point of collection, in the field on a mobile device, or before it is accepted into your database.
It prevents bad data polluting the information required for good decisions.
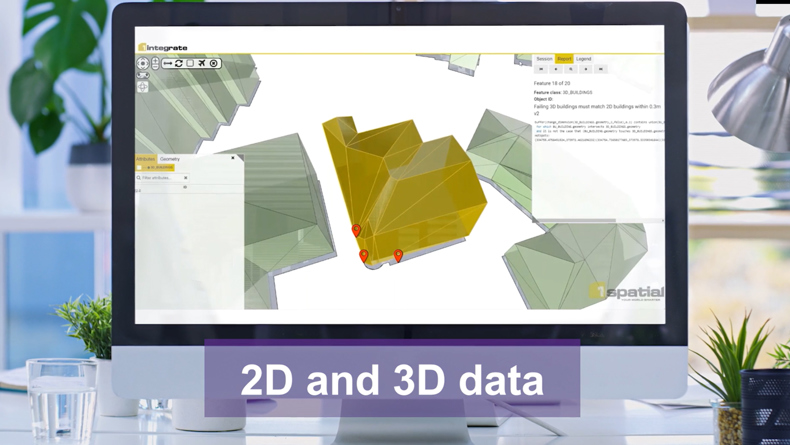
What is data validation?
Data validation is the process of checking the accuracy, integrity and structure of source data by comparing it to a set of defined rules, thereby ensuring that it conforms to specific data quality requirements. Validating your data is essential before migrating, merging or ingesting your data into a system. Ideally, validation should be continuous and automated process to ensure consistency and avoid data loss and errors throughout the data lifecycle.
Validation and data governance
Automation of data validation ensures that the subjectivity that can often occur with more manual validation processes is eliminated. Automation provides a much more efficient way to manage data governance, leaving staff the time to focus on the organisation's actual mission.
Automation of data governance rules also ensures that the data will be continually governed now and in the future, as opposed to an individual project to validate and clean up the data at a single point in time. Automation makes data governance a process rather than an event. And when the data validation rules are established to meet the specific expectations of the data required to accomplish the organisation’s mission, decision makers can feel much more confident in the decisions they make, both big and small.
Speak to a data validation expert
For help getting your data into shape and keeping it that way.
Contact UsValidating geospatial data
Organisations increasingly rely on spatial data, often accessing it in real time to drive decisions from delivery routes to major investment projects.
When your organisation relies on you for reliable data, you need a system that cost-effectively and quickly ensures that the data entering your database conforms with your requirements. Is it accurate, consistent, correct, current and complete?
Our core business is in making geospatially-referenced data current, accessible, easily shared and trusted. We have over 30 years of experience as a global expert; uniquely focused on the modelling, processing, transformation, management, interoperability, and maintenance of spatial data – all with an emphasis on data integrity, accuracy and on-going quality assurance.
We have provided spatial data management and production solutions to a wide range of international mapping and cadastral agencies, government, utilities and defence organisations across the world. This gives us unique experience in working with a plethora of data (features, formats, structure, complexity, lifecycle, etc.) within an extensive range of enterprise-level system architectures.
Data validation using 'no-code' rules
1Spatial's rules-based data validation approach allows the user to define and manage rules against which all data is tested.
- The rules are held in a single, central, technology-neutral repository and can be run against new data on demand.
- They can run in the background as a surveyor collects new data on the ground, flagging when new entries don’t conform with the requirement. This enables the data to be checked there and then, without the need for costly re-visits.
- The rules can also run on batches of data as they are submitted – but before they are added to your core data.
- Data can even be fixed automatically, on the fly, based on the same rules so that good data is quickly integrated, and exceptions flagged for manual review.
- Our enterprise-wide, cross-platform automation quickly and cost-effectively protects your core data asset, helping to make your data smarter.
A powerful rules engine
Our rules-based approach is supported by our patented technology, 1Integrate. Rules are created, tested and released from within a no-code environment.
This environment gives us a highly configurable logic-based data validation and manipulation engine based on user-defined rules as well as an Enterprise Metadata Repository that provides a central, unified location for storing ontologies, rules and process definitions as well as an archive of processing results.
With 1Integrate, users can:
- Define data stores to access data from external data sources
- Configure schema mapping to specify how the data should be organised
- Run rule discovery to identify potential rules from patterns in your data
- Use the rule builder to define rules that apply to your data
- Define actions to correct data that does not conform to your rules
- Set up action maps to specify when actions should be applied
- Define sessions to implement data processing workflows
1Integrate is our patented rules engine to automatically validate, correct, transform and integrate spatial and non-spatial enterprise data
Data validation rule scenarios
Rules can be used in a wide range of scenarios, as you look to establish control, consistency and confidence in your data.
- Powerful spatial and non-spatial rules to easily manage, validate and process data by considering not just individual features but the relationships between them
- Content from existing rules and actions can be re-used to speed up the authoring of new rules
- Topology rules for structuring and snapping your data
- Rules can be defined to create a network graph of your data so you can analyse global connectivity across objects in your data
- Positional Data Shifting - Shift data to deliver positional accuracy improvements using powerful rule algorithms
- Define data models with class hierarchy (ontologies) to easily apply rules and re-use existing rules
Download e-book: Little Book of Spatial Data Infrastructure
Find out how to effectively observe, track, maintain and manage data assets within an organisation's lifecycle, harnessing the power of a Spatial Data Infrastructure (SDI).
Download now